 |
 |
| IFA ROE |
|
Home |
Overview |
Browser |
Access |
Login |
Cookbook |
|
Data Overview
The OSA holds processed OMEGACAM data primarily originating from the VST ATLAS Public Survey (see the VST Public Survey pages for brief descriptions).The underlying content and schema of the archive are described below.
The OSA consists of a series of database releases. For information on these releases, content and sky coverge see the surveys page and coverage maps page.
Users of the OSA data should note the limitations and known issues detailed under the release history.
Summary:
The pixel/image data are held in pipeline processed
multi-extension FITS files (multiframes). Compressed library jpegs images
are also generated and stored.
OSA catalogue data are housed in a relational database running on
Microsoft SQL Server 2008. Data are stored in tables
which are inter-linked via reference ID numbers. In addition to
the main astronomical object catalogues these tables
also contain the meta-data of the multiframe images and calibration
information.
The following sections discuss the structure and content of the OSA database. Further details can be found using the schema browser.
Jump to:
- Detailed overview
- Tables
- Creating the merged tables (source merging and seaming)
- Quality error bit flags
- Magnitudes
OSA - Detailed Overview
MultiframesThe primary component of the OSA is the multiframe which is represented by and stored on disk as a multi-extension FITS (MEF) file. The most common multiframe is a pipeline reduced OMEGACAM observation in a single passband. Typically the associated FITS file will contain a primary extension and 32 image extensions each representing one of the OMEGACAM detectors. If the multiframe has associated object catalogue data then these are held in a separate MEF file.
Users wishing to work with the flat-files directly (i.e. the FITS images and catalogues) might find the flat file page helpful.
Multiframes will exist for all observation types e.g. darks, flats, science etc and data products e.g. stacks, mosaics, difference images etc. It should be noted that the FITS image extensions are mainly held as RICE compressed binary table extensions and that not all multiframes will have 32 image extensions e.g. any mosaics/tiles.
Multiframes are described in the database by entries in three main tables. The multiframe table primarily holds the meta-data that are applicable to a multiframe as a whole rather than an individual detector e.g. basic observation details. These meta-data originate from the primary header of the MEF file. Every multiframe held in archive is represented by a single row in the multiframe table with the attributes/columns in the row holding the meta-data. The multiframeDetector table contains details applicable to individual detector frames that are part of a multiframe. The third main table, currentAstrometry, contains the current astrometric calibration coefficients (WCS) for each science detector frame that is again part of a multiframe. If a multiframe has 32 detectors/extensions there will be 32 corresponding entries (rows) in multiframeDetector and currentAstrometry. A schematic representation of a multiframe is shown above
Each multiframe is assigned a unique ID number multiframeID which is an attribute in many tables held in the archive including each of the three tables discussed above (multiframe, multiframeDetector and currentAstrometry). The multiframeID number is used, often in conjunction with the extension number attribute (extNum) to link the multiframe records held across the tables.
An example: A stacked G-band OMEGACAM science observation at a single pointing is generated by the pipeline which produces a MEF file that holds the image data and a MEF file holding the catalogue data. This observation constitutes a multiframe and is assigned a multiframeID, say 12345, at ingest into the archive. A single row entry is written into the multiframe table, attributes in the row include the multiframeID, the filename of the image MEF file, the filename of the catalogue MEF file, the number of detectors/extensions (in this case 32) and observational meta-data. For every detector/extension in the multiframe, rows are written into multiframeDetector and currentAstrometry tables. Each of the 32 rows written into these two tables contains the same multiframeID (12345) and the relevant extension number (numbered 2-32). So if we want to find the WCS coefficients for the 10th detector in this multiframe we would need to query the currentAstrometry table looking for a row that has multiframeID=12345 and extNum=11.
Catalogue data
Objects produced when source extraction is performed on a multiframe are
ingested, one object per row, into the relevant survey detection table
(see tables below). The detection table also holds
the catalogues generated from deep stacks of repeated observations.
All the survey detection tables contain similar
attributes/columns with each row representing an object
detected in one waveband at one epoch. Source merging (see
Creating the merged tables)
is carried out on the detection tables to produce the corresponding
survey source table.
A log of the source merging for a given survey is recorded in a further
table.
The source table holds an object's multi-waveband,
multi-epoch parameters in one row. The source tables for different surveys
contain different attributes as each survey requires a particular set
of observations. For example the ATLAS survey requires observations in u, g, r, i, z.
To help reduce the width of the source tables the attributes held for an object in
a given waveband/epoch is a subset of those recorded in the detection
table. To recover the full set of parameters multiframeID,
frameSetID and SeqNum numbers are provided to allow cross-referencing.
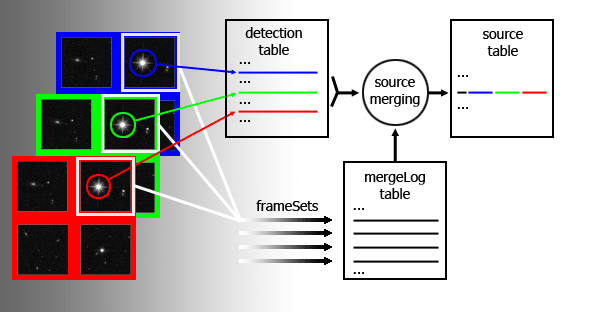
Schematic diagram of source merging via a frameSet (only 4 of the 32 detectors shown)
Taking ATLAS as an example, the detections are held in atlasDetection, the source merging is recorded in atlasMergeLog and the merged sources placed in atlasSource. Imagine that three multiframes, taken in u, g, and r and covering approximately the same part of the sky, are produced by the pipeline. The multiframeIDs are say 12345, 23456 and 34567 respectively. Objects detected on each multiframe are loaded into atlasDetection. The multiframes are run through source merging which produces an entry in atlasMergeLog for each set of paired multiframe extensions. Typically the first extension in u will be paired with the first extensions of g and r. So looking at the pairing of the first extensions atlasMergeLog will contain an entry with a unique frameSetID, say 98765, which has attributes umfID=12345, ueNum=2, gmfID=23456, geNum=2, rmfID=34567 and reNum=2. The records written into atlasSource by this pairing will all have frameSetID=98765. If we wanted to examine the full g band detection attributes of a given source in atlasSource that had say an gSeqNum=87654 we would first need know the extNum (e.g. 2) and g multiframeID (e.g. 23456), available by querying atlasMergeLog for frameSetID=98765 and then query atlasDetection for the entry corresponding to multiframeID=23456 extNum=2 and seqNum=87654.
The above description attempts to give users an overview of the tables they are most likely to use. The schema browser should be used to further explore the contents and layout of the archive.
OSA - Tables
The main tables that users are likely to query for a given survey are the corresponding source and/or detection table
| Survey | Source table | Detection table |
| Commissioning data | commSource | commDetection |
| ATLAS | atlasSource | atlasDetection |
Source tables contain merged records for a given object in the passbands that define the survey. Detection tables contain full details on the individual passband/epoch measurements. The source and detection tables are linked via reference ID numbers held as parameters.
OSA - Source merging and seaming
Individual passband detections that come from OMEGACAM images and that are stored in the *Detection tables in the OSA are automatically merged into multi-colour source lists stored in the *Source tables. The set of passbands is predefined for each survey and stored in the table RequiredFilters; that prescription is used to associate individual passbands/epochs into frame sets.
The core of the source merging algorithm uses a simple pairing procedure
between pairs of frames before producing the final merged list. For a given
frame set, frames are considered in pairs (say frames A and
B) moving from short to long wavelengths, and early to late epochs
where appropriate, and pairs are made by looking for the nearest detection
in B for every detection in A out to a maximum pairing
tolerance specified for each survey. The default pairing radius is
usually 2.0 arcsec (used for ATLAS). The pairing criterion for
each programme is stored in table PROGRAMME in attribute
pairingCriterion; note that this is in units of degrees. To
find out the pairing criteria in arcsec for the programmes that form part of
a released database product, simply use the following SQL:
SELECT dfsIDString,description,pairingCriterion*3600.0 AS radius
FROMProgramme
The pairing is only considered as safe if the detection in B is the nearest to the detection in A, AND if the detection in A is the nearest to the detection in B: i.e. two sets of pointers of the nearest object in B to every object in A, and vice versa, are produced, and only consistent pair pointers are used to associate pairs of objects. If detection Y in B is the nearest as seen from the position of detection X in A, but detection Z in A is the nearest as seen from the position of Y in B, then the association is not made and detection X in A will not be paired to any in B.
Source merging then proceeds when all pair combinations of available passbands in the frame set have had consistent pointer sets produced. The merging procedure is simply to start with the shortest wavelength detection set as a master set, and merge in the pairs pointed to by each of the slave pointer sets; subsequently, the next shortest wavelength set is considered as the master, and all detections not already merged in previously are considered as slaves amongst the remaining passband sets. This process continues until only unmerged detections in the final passband set are left, and these are written into the merged source list. Hence, every detection amongst all the images in the frame set will have one, and only one, entry somewhere amongst the set of merged sources.
Note that the pairing radius is large compared to the typical
astrometric errors (and may be too large for a given science application).
This is in order that moving sources (e.g. high proper
motion objects) and sources with unusually high centroiding errors
(e.g. very faint and/or extended, low surface brightness objects) will be
paired up in the merged source lists. The negative side to this is that
some level of spurious matchings will inevitably
occur. For well exposed, non-moving
sources, some indication of the reliability of the merged set can be
checked at usage (query) time by applying filters to the *Xi and
*Eta attributes in the *Source table. These attributes
provide the offset from master to slave for pairings, in arcsec, and should
not be larger than about 1 arcsec for non-moving, well exposed sources. If
your particular science application requires a more restrictive pairing
tolerance, then simply tune by selecting on *Xi and
*Eta at query time:
SELECT...WHERE jXi BETWEEN -1.0 AND +1.0 ...
etc.
Seaming - the final stage in the source table creation is to perform
seaming which flags duplicate objects by populating the priOrSec (primary or secondary) flag.
Matching objects in overlap regions are ranked according to their filter coverage then their
quality error bit flags and finally their proximity to a detector edge. For example say the same source is found
on three overlapping framesets having framesetID = X, Y and Z. Framesets Y and Z have coverage in u,
g and r bands and X only has the u band. The quality error bit information (*ppErrBits) shows that
more confidence can be
placed in the source produced by frameset Y. The conclusion for this source is that the measurement taken
from frameset Y is the primary and those taken from X and Z are secondary. The priOrSec flag for
all three sources is set to framesetID Y. Sources that do not have duplicate measurements have
priOrSEc=0. The SQL where clause to select only primary sources (i.e. purge duplicates) is
.... where (priOrsec=0 or priOrSec=framesetID)
OSA - Quality Error bit flagging
Quality error bit attributes in the Detection and Source tables flag the confidence of a given detection or source. The attributes and the meaning of the values assigned during WFAU post-processing are described on ppErrBits. Examples of how the quality error bit flags can be used in queries are given in the SQL cookbook.OSA - Magnitudes
Kron and Petrosian magnitudes are underestimated for large galaxies, because the aperture is limited to the largest aperture radius, aperRad13 = 12 arcsec. This is the approximately the same size as the background estimation mesh, so larger apertures risk producing large errors due to poor background subtraction. There are a small number of bright objects which do have larger Kron and Petrosian radii. Most of these are flagged as saturated, but a small number (a few tens) have no errors. Generally these are isolated large, bright galaxies. It should be noted that the value of kronRad is the first moment of the surface brightness profile and the value of petroRad is when the radius at which the surface brightness in an annulus is 0.2 times the mean surface brightness. The apertures in which the flux is calculated is twice this radius in both cases.
Home | Overview | Browser | Access | Login | Cookbook
Listing | FreeSQL
Links | Credits
WFAU, Institute for Astronomy,
Royal Observatory, Blackford Hill
Edinburgh, EH9 3HJ, UK
osa-support@roe.ac.uk
23/4/2015